Meta cloned OpenClaw. The clown car erupted. Horns honking about betrayal, theft, the death of fair acquisition. Armchair VCs tripping over each other to declare how the industry failed. I watched the circus and felt something different entirely.
You cannot acquire something no human owns.
The Valley of Stupidity Test
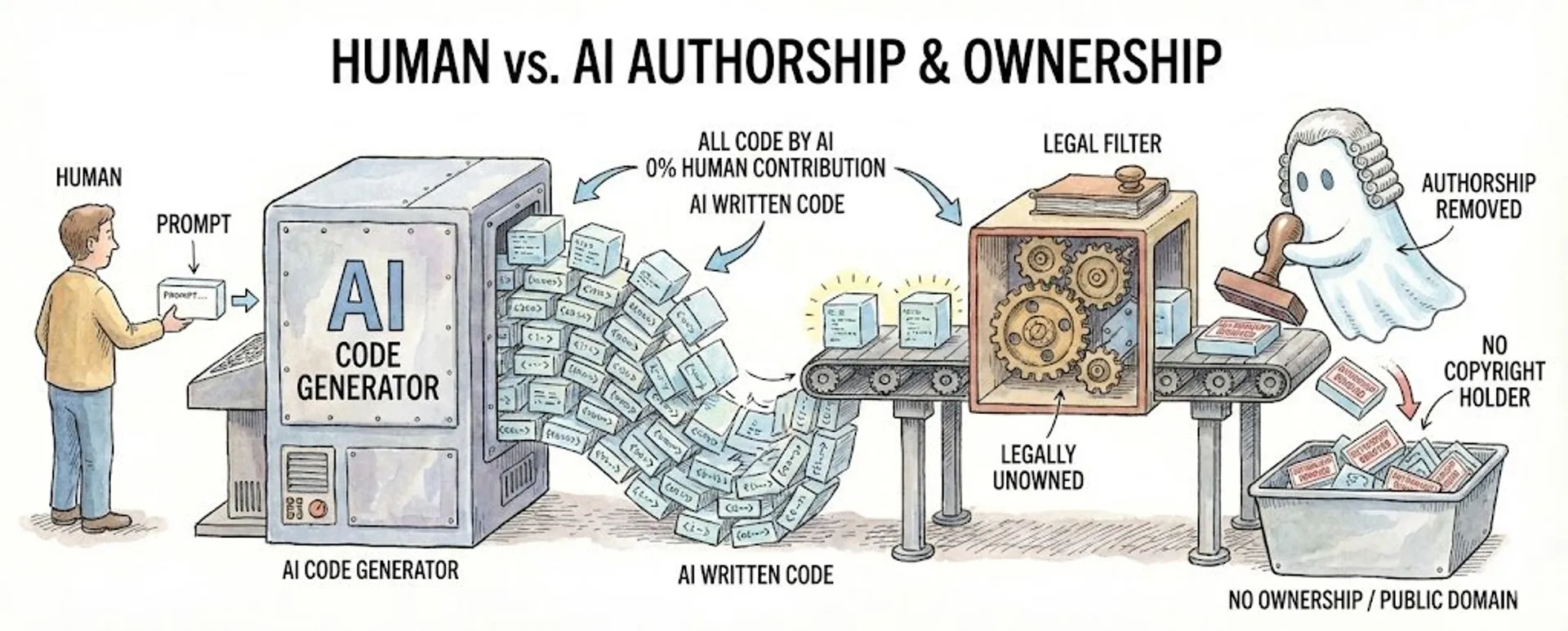
Walk through it with me. You open a terminal. You type a prompt. The LLM generates code, hundreds of lines, sometimes thousands, assembled from statistical patterns trained on billions of lines of other people’s work. You copy it into a repo. Slap an MIT license on it. Push to GitHub.
Where in that chain did you become the author?
I keep calling this the Valley of Stupidity Test because the answer should be obvious and yet an entire industry refuses to see it. The US Copyright Office laid it out in March 2023. Prompting an AI is not authorship. A human must exercise creative control over the expressive elements of the work. Not the idea. Not the architecture. Not the prompt. The actual arrangement of words and symbols that constitute the output.
The DC District Court drove the nail deeper in Thaler v. Perlmutter on August 18 2023. Stephen Thaler argued his AI system DABUS should be recognized as an author. The court said no. The Copyright Act requires human authorship. Full stop. Thaler has petitioned the Supreme Court. If they decline to hear it, this doctrine calcifies for a generation.
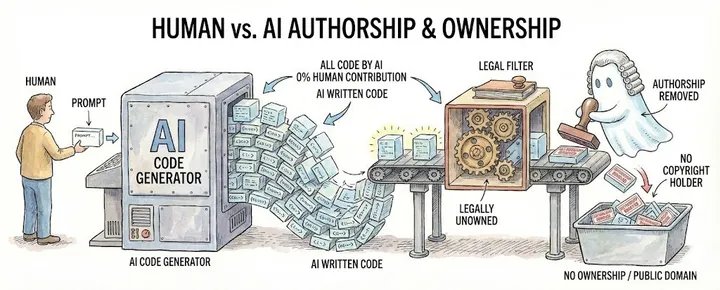
The Copyright Office acknowledged that works mixing human and AI elements can receive partial protection. Only the human authored portions qualify. The AI generated portions sit in the public domain. So the question for every repo becomes: what percentage did you actually write? Not direct. Not review. Write.
The License Is a Costume
This is the part that should keep founders awake. Open source licenses are built on copyright. The MIT license grants permissions that only a copyright holder can grant. The GPL mandates share alike provisions rooted in the holder’s exclusive rights. Every open source license ever written assumes someone owns the underlying work.
Rip that assumption out and the whole scaffold collapses onto itself.
If you prompted an LLM to generate your codebase, you do not hold copyright over that output. You cannot grant licenses you do not possess. The MIT badge on that README is decoration. The LICENSE file is a prop on a stage with no play. Anyone downstream relying on those terms is building on a foundation that legally does not exist, because the grantor had nothing to grant.
If a codebase is majority generative, meaning no human authorship, then said human ownership is void.// The uncomfortable truth
The counterargument writes itself. “I made creative decisions. I chose the architecture. I guided the refactors. I reviewed the pull requests.” Fine. Maybe you did. The Copyright Office might grant you protection over whatever fraction of the codebase you personally expressed. The rest? Public domain. Unowned. Up for grabs.
The Self Deposition
Here is where it turns from abstract to personal. The creator of the project in question went on Lex Fridman’s podcast and said, in his own words:

I got more and more comfortable that I do not have to read all the code. I do not read the boring parts of code.// Lex Fridman Podcast
That sentence is not a productivity flex. It is a legal confession.
When you publicly state that you do not read the code your agents produce, you surrender any plausible claim to creative control over the expression. You directed the outcome. You did not author the work. Copyright law does not care about your intentions or your architecture diagrams. It protects specific expression. The expression came from the model.
Every founder shipping a majority AI codebase should imagine their Slack messages, their podcast transcripts, their tweets read aloud in discovery.
I told the AI what to build.
That is not the defense they think it is. Played back under oath, it becomes exhibit A for the other side.
The Void Has a Price Tag
Venture capital is pouring into companies whose primary asset is a codebase. If that codebase is majority AI generated, the IP portfolio underpinning the entire valuation may be hollow. Due diligence teams are not yet asking what percentage of the code was human authored. They will start. When they do, some cap tables are going to need uncomfortable conversations.
Acquisition targets built on prompted code carry a specific poison: the acquirer cannot enforce exclusive rights over the software because no exclusive rights exist. A competitor could replicate the entire product by prompting the same models with similar instructions and arriving at functionally identical output. No infringement claim survives, because the original was never protected in the first place.
If you are building a product with heavy AI code generation, track authorship ratios today. Document which modules were human written at the expression level, not the architecture level. Keep records of substantive creative decisions over specific code. The legal landscape will catch up. Your evidence trail needs to be ready before it does.
The licensing model that powered open source for thirty years was built for a world where humans wrote code and machines compiled it. We flipped that. Machines write the code now. Humans compile the prompts. The legal infrastructure has not caught up, and until it does, every AI heavy codebase sits in a void: too synthetic to protect, too derivative to ignore, too valuable to walk away from.
What percentage of your shipping codebase did a human actually write?
// SENSOR_DATA_OVERLAY: FIELD_INTENSITY 0.92Hz
// "The design isn't just a shell; it's a sensory interface for the model's weights."